


Llama 3 70B vs Llama 3.1 70B: 3 > 3.1?
Speed vs Power: Choosing the Right Llama for Your AI Needs


On July 23rd, 2024, Meta released its latest flagship model, Llama 3.1 405B, along with smaller variants: Llama 3.1 70B and Llama 3.1 8B. This release came just three months after the introduction of Llama 3. While Llama 3.1 405B outperforms GPT-4 and Claude 3 Opus in most benchmarks, making it the most powerful open-source model available, it may not be the optimal choice for many real-world applications due to its slow generation time and high Time to First Token (TTFT).
For developers looking to integrate these models into production or self-host them, Llama 3.1 70B emerges as a more practical alternative. But how does it compare to its predecessor, Llama 3 70B? Is it worth upgrading if you're already using Llama 3 70B in production?
In this blog post, we'll conduct a detailed comparison between Llama 3.1 70B and Llama 3 70B, examining their performance, efficiency, and suitability for various use cases. Our goal is to help you make an informed decision about which model best fits your needs.
TL;DR
Llama 3.1 70B: Larger context, better for complex tasks, slower
Llama 3 70B: Faster, efficient for short tasks, limited context
Upgrade to Llama 3.1 70B if you need a larger context; stay if speed is priority
Basic comparison
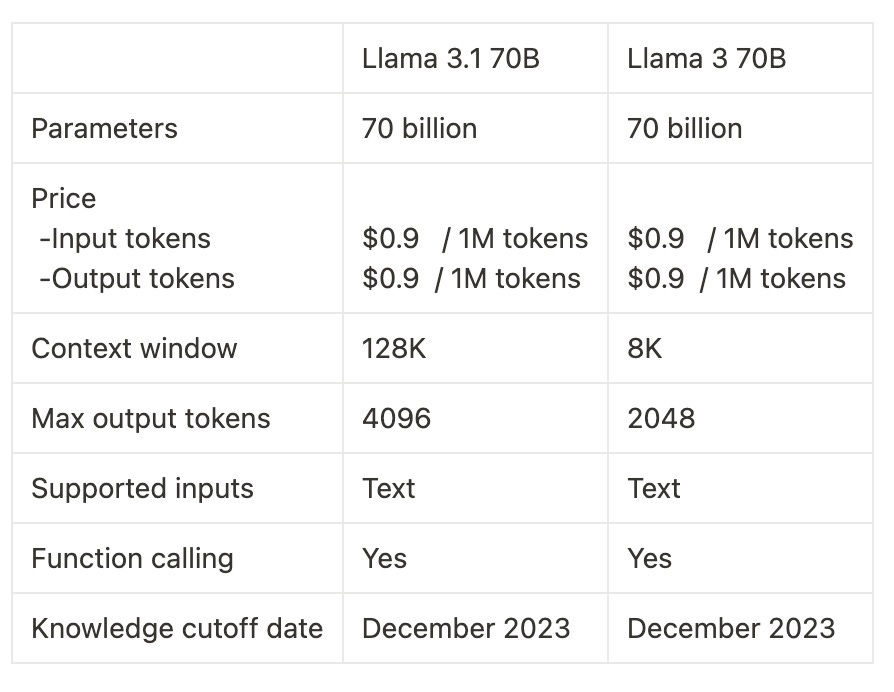
Key Improvements:
Context Window: Llama 3.1 70B - 128K vs Llama 3 70B's 8K (16-fold increase)
Max Output Tokens: 4096 vs 2048 (doubled)
These significant improvements in context window and output capacity give Llama 3.1 70B a substantial edge in handling longer and more complex tasks, despite both models sharing the same parameter count, pricing, and knowledge cutoff date. The expanded capabilities make Llama 3.1 70B more versatile and powerful for a wide range of applications.
Benchmark comparison

Llama 3.1 70B outperforms its predecessor in most benchmarks, with notable improvements in MMLU (+4 points) and MATH (+17.6 points). It shows a slight edge in GSM8K (+2.1 points). However, Llama 3.1 70B slightly underperforms in HumanEval (-1.2 points), suggesting a marginal decrease in coding performance. Overall, Llama 3.1 70B demonstrates superior performance, particularly in mathematical reasoning tasks, while maintaining comparable coding abilities.
Speed comparison
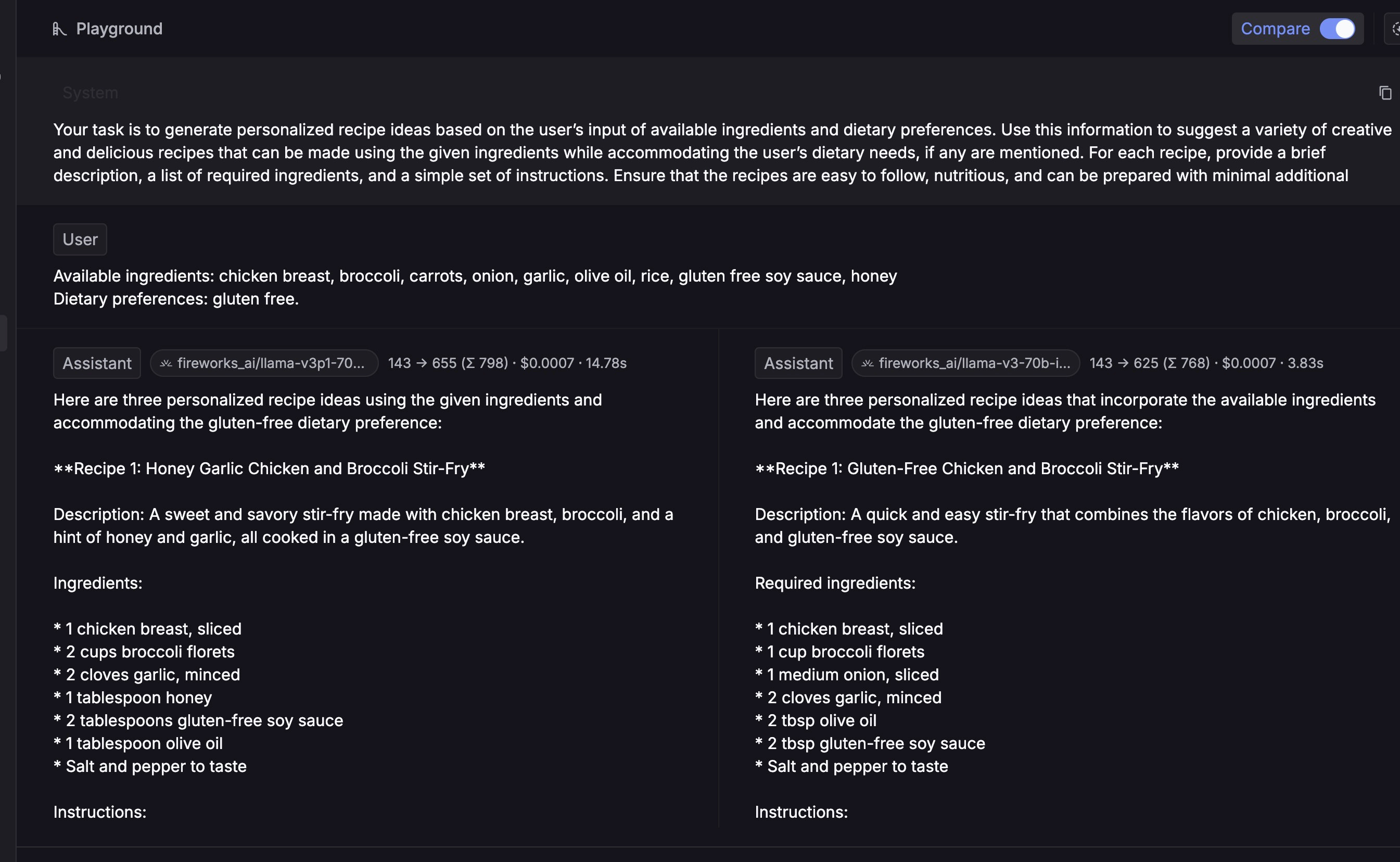
We conducted tests using Keywords AI’s model playground to compare the speed performance of Llama 3 70B and Llama 3.1 70B.
Latency
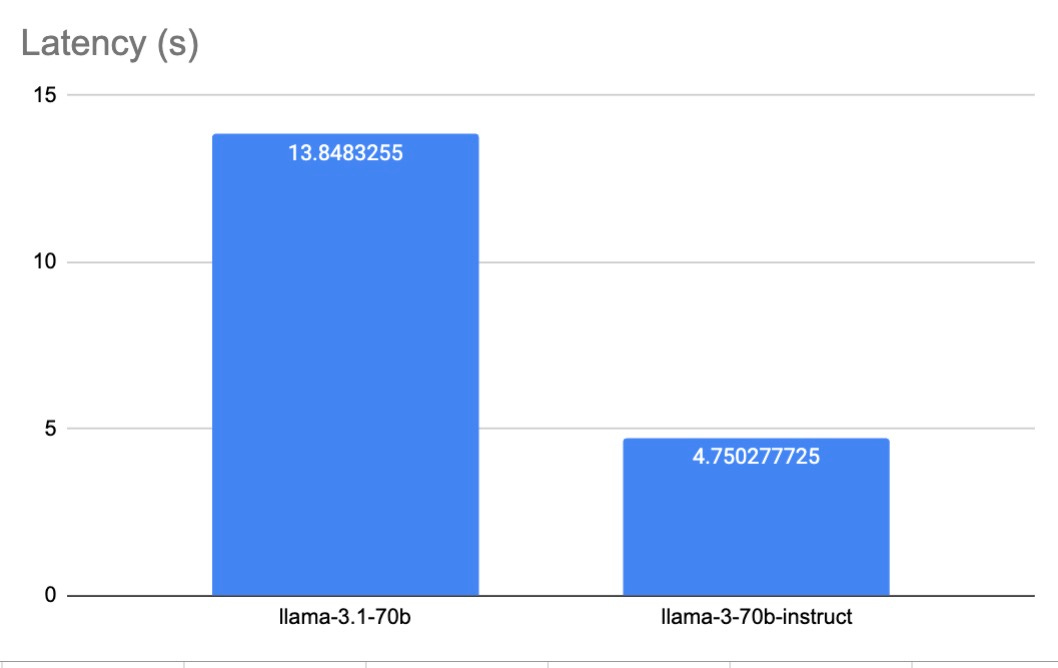
Our tests, consisting of hundreds of requests for each model, revealed a significant difference in latency. Llama 3 70B demonstrated superior speed with an average latency of 4.75s, while Llama 3.1 70B averaged 13.85s. This nearly threefold difference in response time highlights Llama 3 70B's advantage in scenarios requiring quick real-time responses, potentially making it a more suitable choice for time-sensitive applications despite Llama 3.1 70B's improvements in other areas.
TTFT (Time to first token)
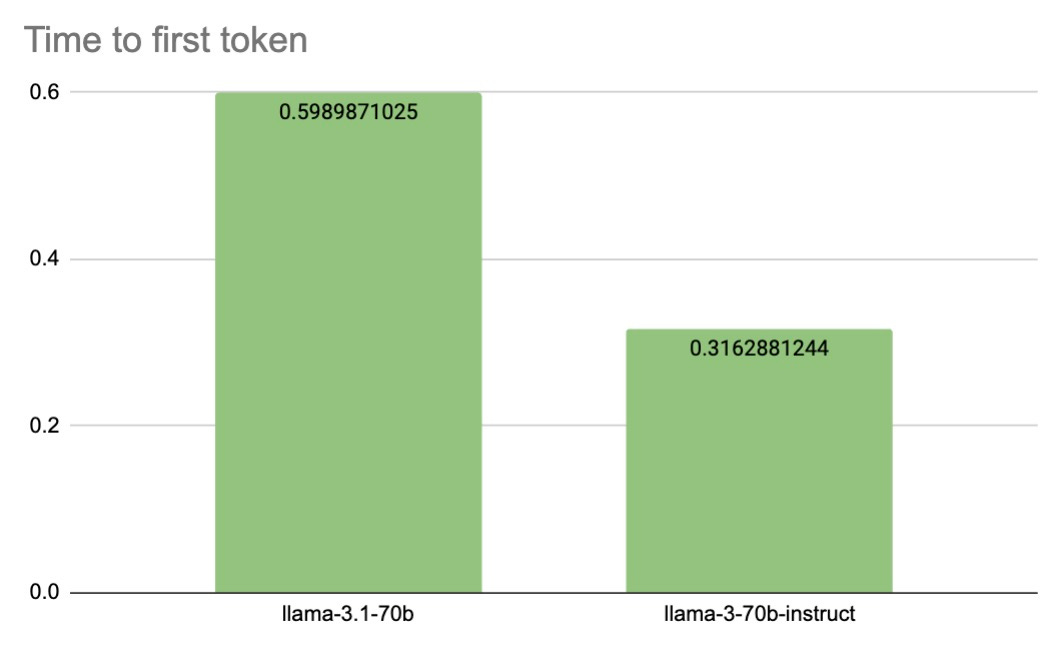
Our tests reveal a significant difference in TTFT performance. Llama 3 70B excels with a TTFT of 0.32s, while Llama 3.1 70B lags at 0.60s. This twofold speed advantage for Llama 3 70B could be crucial for applications requiring rapid response initiation, such as voice AI systems, where minimizing perceived delay is essential for user experience.
Throughput (Tokens per second)
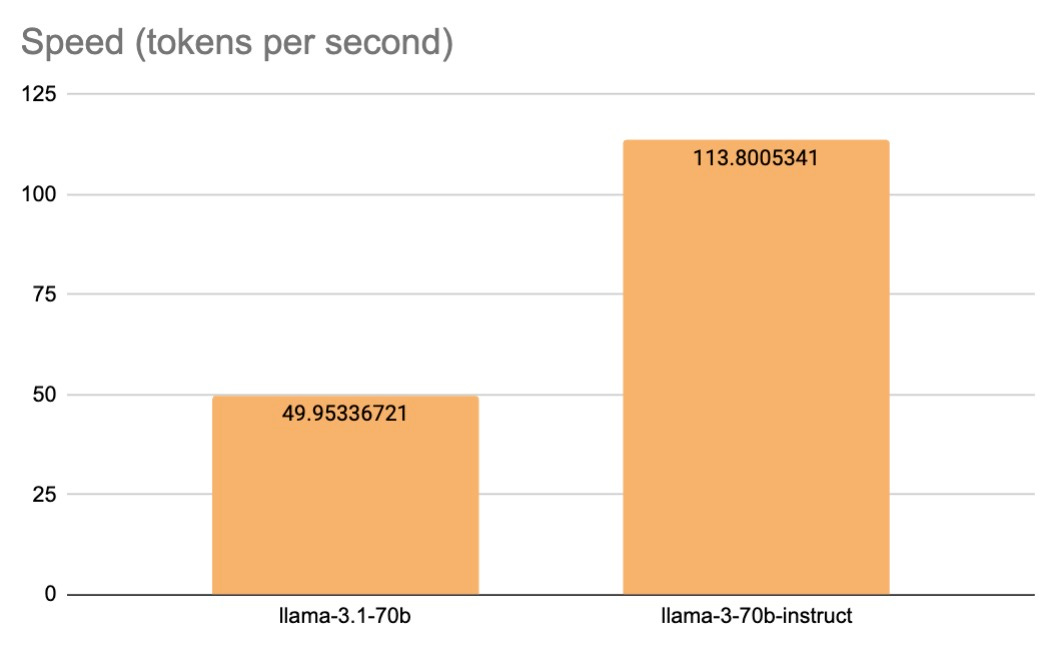
Llama 3 70B demonstrates significantly higher throughput, processing 114 tokens per second compared to Llama 3.1 70B's 50 tokens per second. This substantial difference in processing speed - more than double - underscores Llama 3 70B's superior performance in generating text quickly, making it potentially more suitable for applications requiring rapid content generation or real-time interactions.
Performance comparison
We conducted evaluation tests on the Keywords AI platform. The evaluation comprised three parts:
Coding Task:Both models successfully completed frontend and backend development tasks. Llama 3 70B often produced more concise solutions with better readability.
Document Processing: Both models achieved high accuracy (~95%) in processing documents ranging from 1 to 50 pages. Llama 3 70B demonstrated significantly faster processing speeds but was limited to documents under 8-10 pages due to its smaller context window. Llama 3.1 70B, while slower, could handle much longer documents.
Logical Reasoning: Llama 3.1 70B outperformed Llama 3 70B in this area, solving most problems more effectively and showing superior ability in identifying logical traps.
Model Recommendations
Llama 3.1 70B
Best for: Long-form content generation, complex document analysis, tasks requiring extensive context understanding, advanced logical reasoning, and applications that benefit from larger context windows and output capacities.
Not suitable for: Time-sensitive applications requiring rapid responses, real-time interactions where low latency is crucial, or projects with limited computational resources that cannot accommodate the model's increased demands.
Llama 3 70B
Best for: Applications requiring quick response times, real-time interactions, efficient coding tasks, processing of shorter documents, and projects where computational efficiency is a priority.
Not suitable for: Tasks involving very long documents or complex contextual understanding beyond its 8K context window, advanced logical reasoning problems, or applications that require processing of extensive contextual information.
Where to try these open-source models?
Self-hosting open-source models has its own strengths, offering complete control and customization. However, it can be inconvenient for developers who want a simpler and more streamlined way to experiment with these models.
Consider using Keywords AI, a platform that allows you to access and test over 200 LLMs using a consistent format. With Keywords AI, you can try all the trending models with a simple API call or use the model playground to test them instantly.
 | A guest post by
|